Stage 4: Imitation Learning and Real-World Deployment
Overview
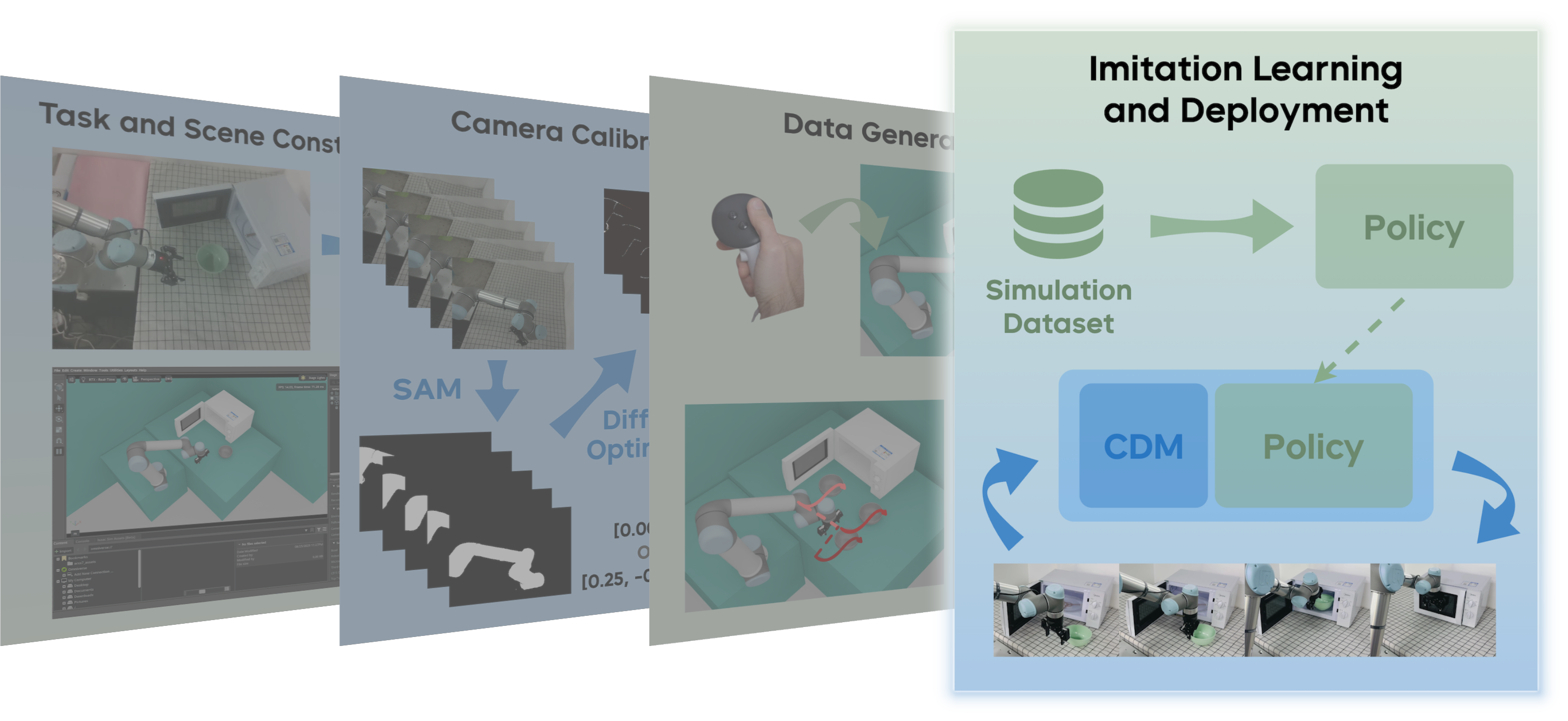
This stage leverages the generated demonstration data to train visuomotor control policies via imitation learning, enabling direct transfer to physical systems. We employ a depth-based variant of the PPT (Perception-Policy-Transfer) framework[1,2], utilizing depth representations as the primary visual modality for enhanced sim-to-real transfer.
Policy Training
Our architecture adapts a pre-trained ResNet encoder for depth image processing (with modified single-channel input layer), combines proprioceptive state encoding via MLP, and employs a diffusion head for action sequence generation[1,2]. The policy learns temporal action distributions from Stage 3 demonstrations, achieving robust task completion in simulation:
Real-World Deployment
Deployment utilizes ManiUniCon, an asynchronous control framework that decouples perception, inference, and actuation into parallel processes, minimizing latency and ensuring smooth trajectory execution despite computational overhead.
Depth Prediction via CDMs
Physical depth sensors exhibit significant noise characteristics absent in simulation, creating a domain gap that degrades policy performance. We mitigate this through Camera Depth Models (CDMs)—neural architectures that synthesize high-fidelity depth maps from RGB inputs. These models leverage learned geometric priors to produce depth representations comparable to simulated quality, facilitating robust sim-to-real transfer.
Code Reference
Policy Architecture:
- Configuration:
https://github.com/universal-Control/ppt_learning/blob/main/configs/config_eval_depth_unified.yaml
ManiUniCon Framework:
- Control pipeline:
https://github.com/Universal-Control/ManiUniCon/blob/main/main.py - Hardware interface:
https://github.com/Universal-Control/ManiUniCon/blob/main/maniunicon/robot_interface/ur5_robotiq.py
CDM Integration:
- Observation processing:
https://github.com/Universal-Control/ManiUniCon/blob/main/maniunicon/customize/obs_wrapper/ppt_depth_wrapper_cdm.py
References
[1] Pu Hua, Minghuan Liu, Annabella Macaluso, Yunfeng Lin, Weinan Zhang, Huazhe Xu, and Lirui Wang. GenSim2: Scaling robot data generation with multi-modal and reasoning LLMs. arXiv preprint arXiv:2410.03645, 2024.
[2] Haotong Lin, Sida Peng, Jingxiao Chen, Songyou Peng, Jiaming Sun, Minghuan Liu, Hujun Bao, Jiashi Feng, Xiaowei Zhou, and Bingyi Kang. Prompting depth anything for 4k resolution accurate metric depth estimation. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 17070–17080, 2025.