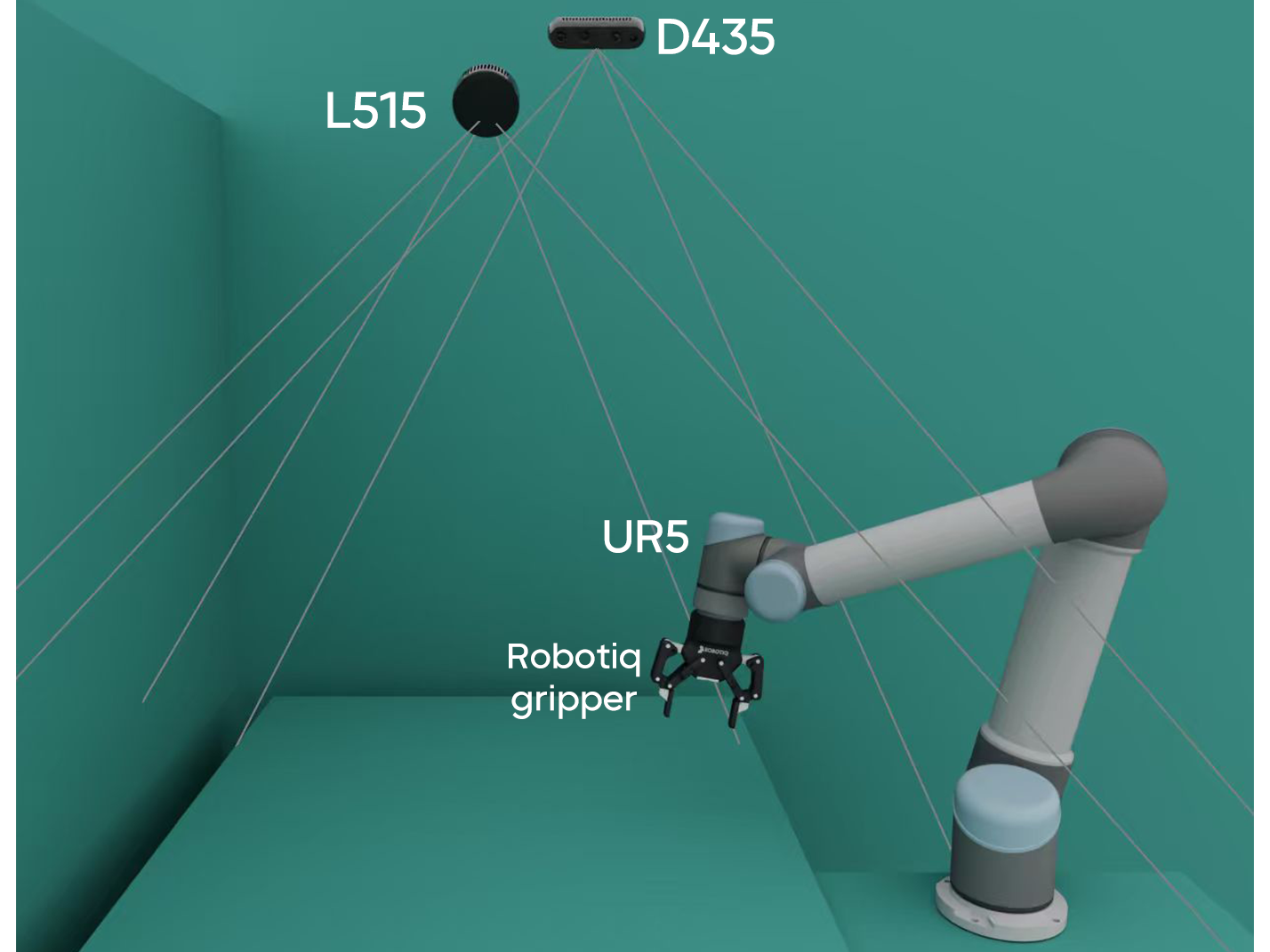
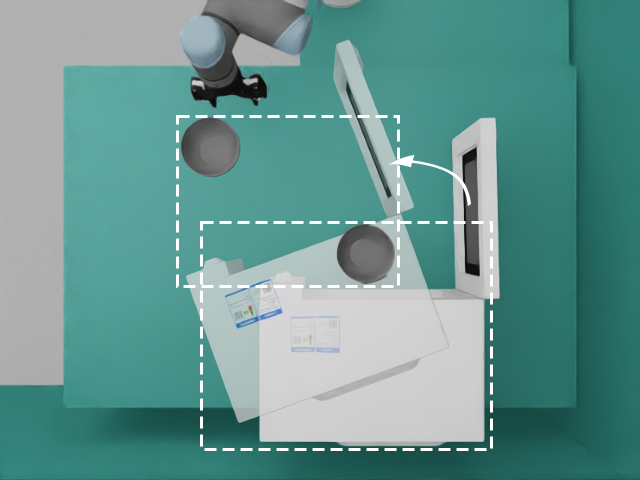
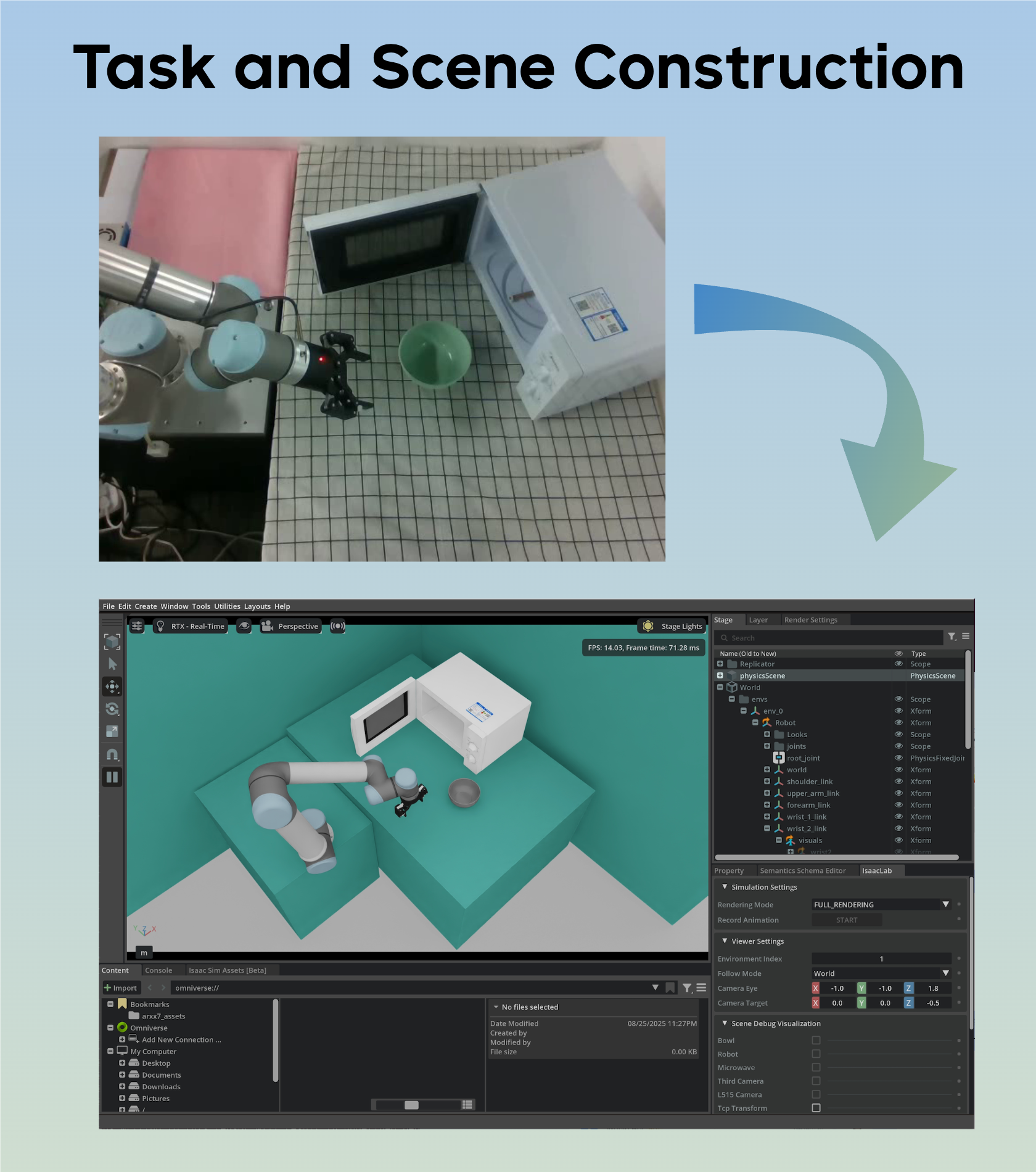
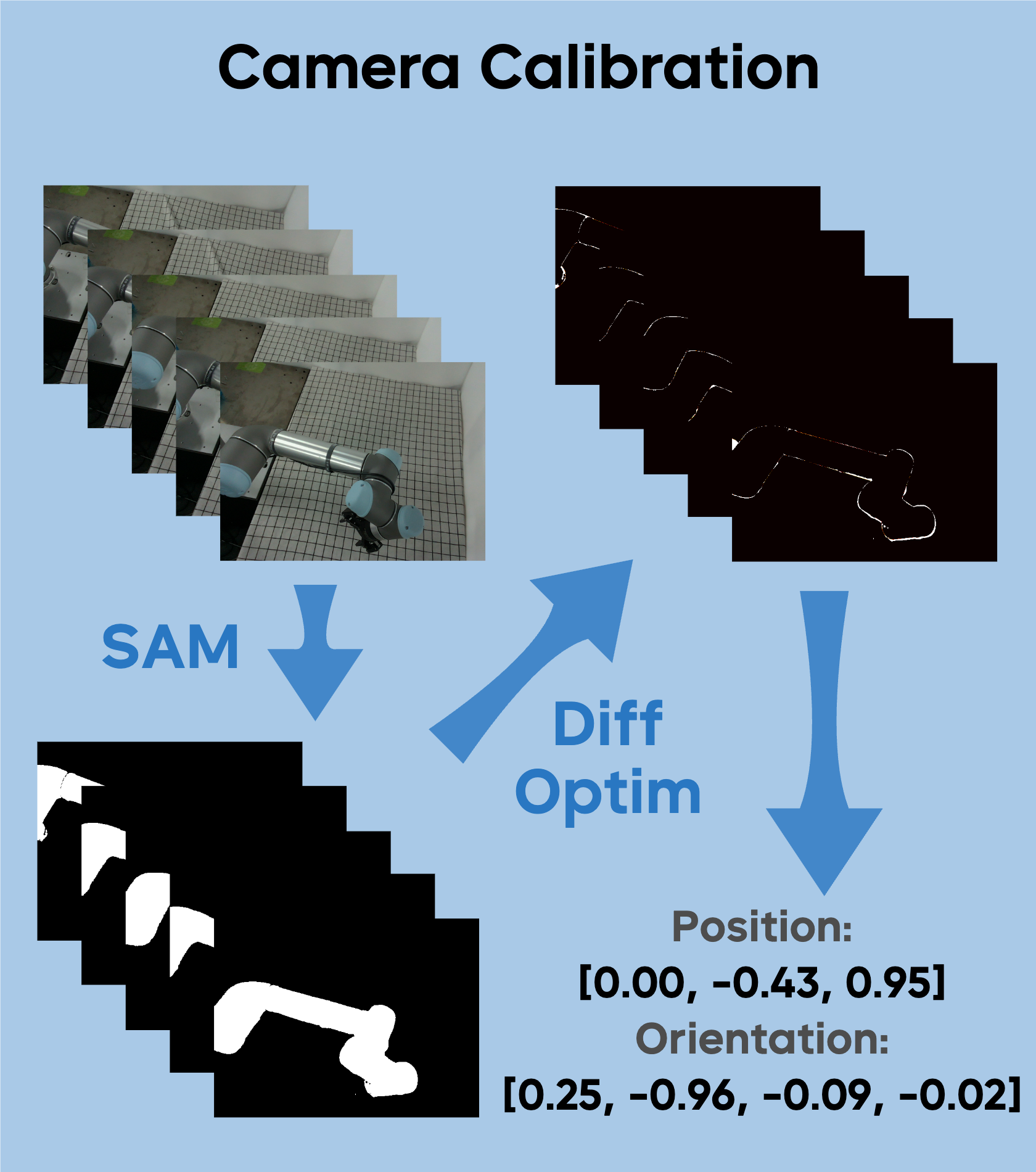
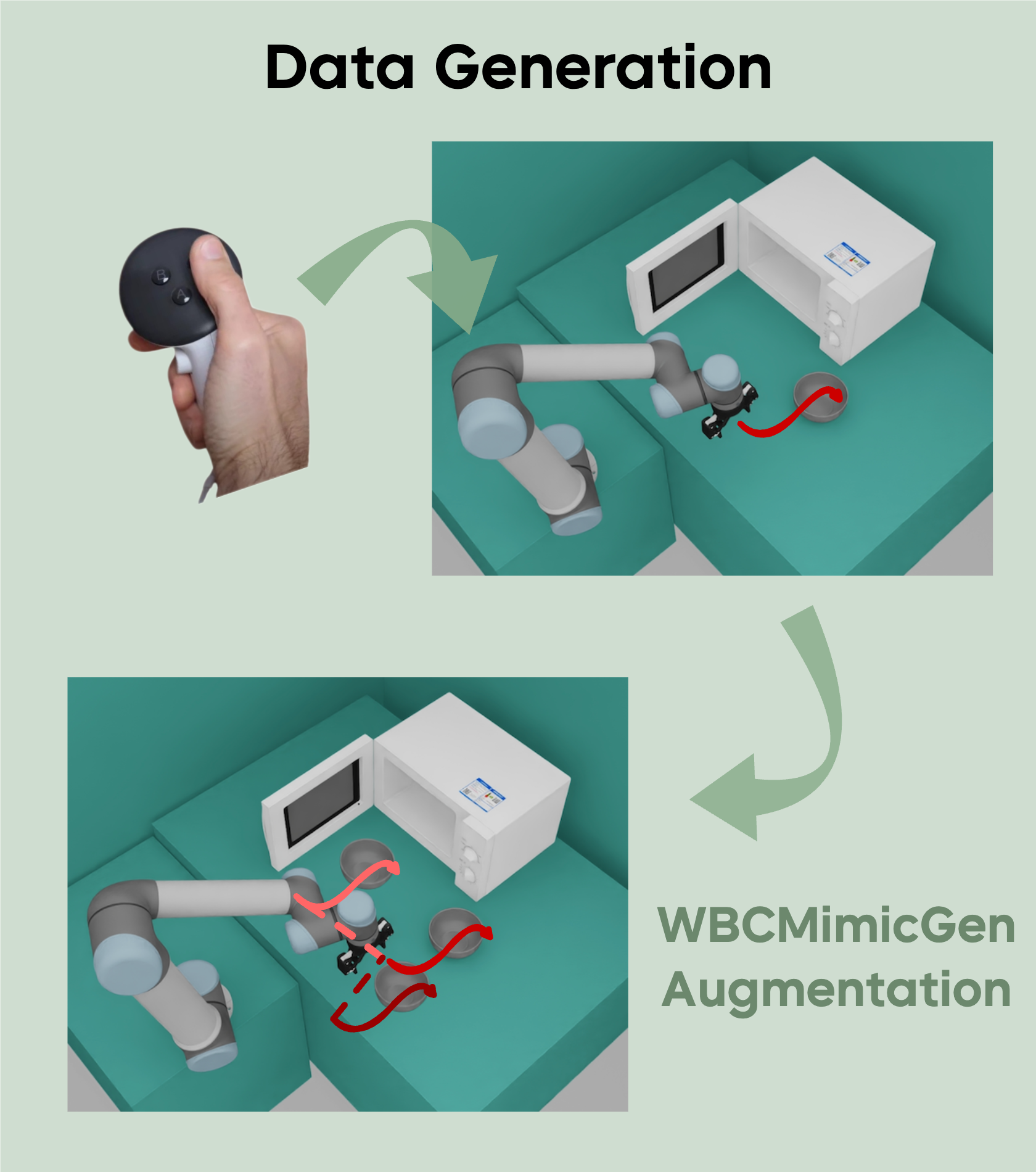
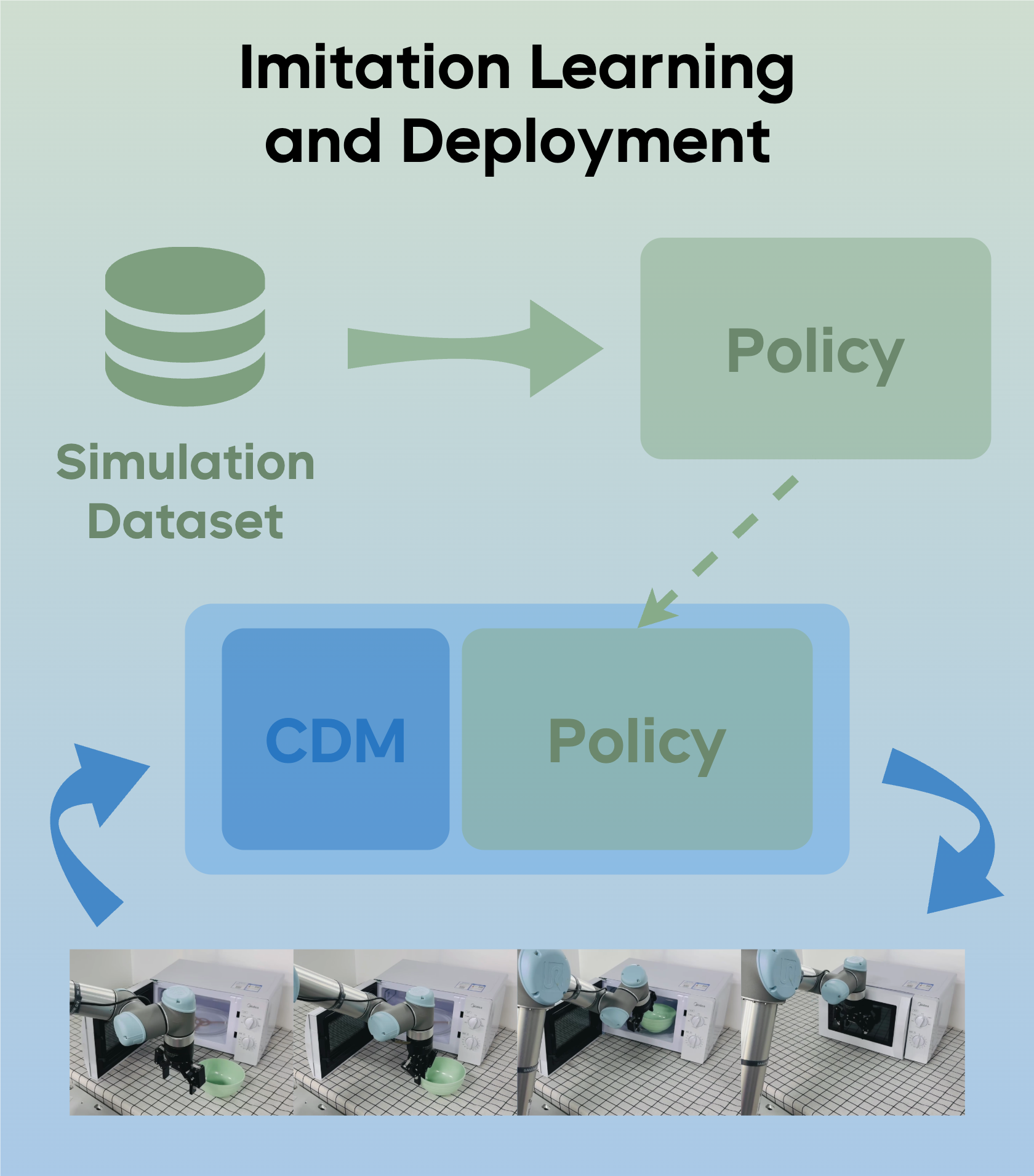
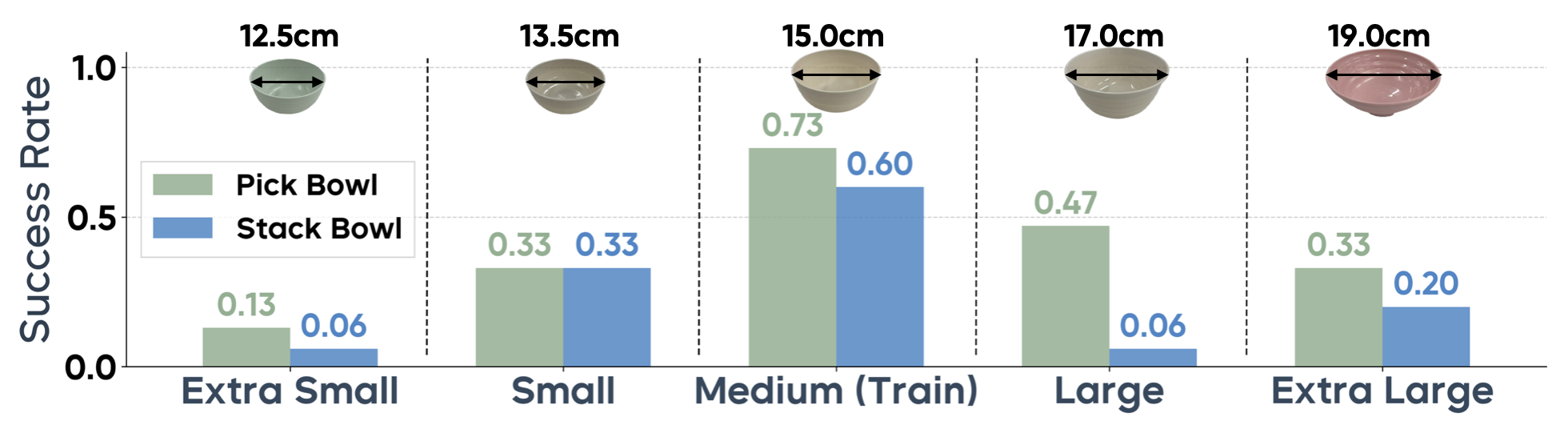
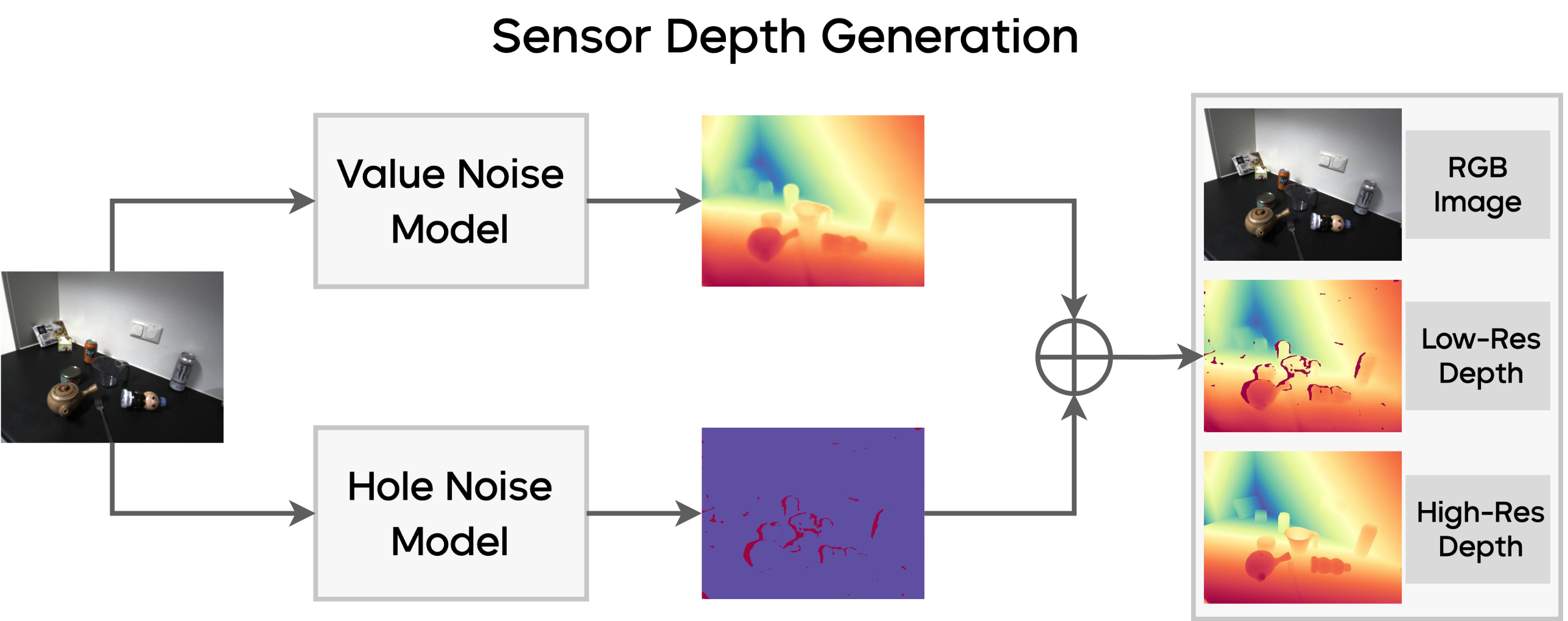
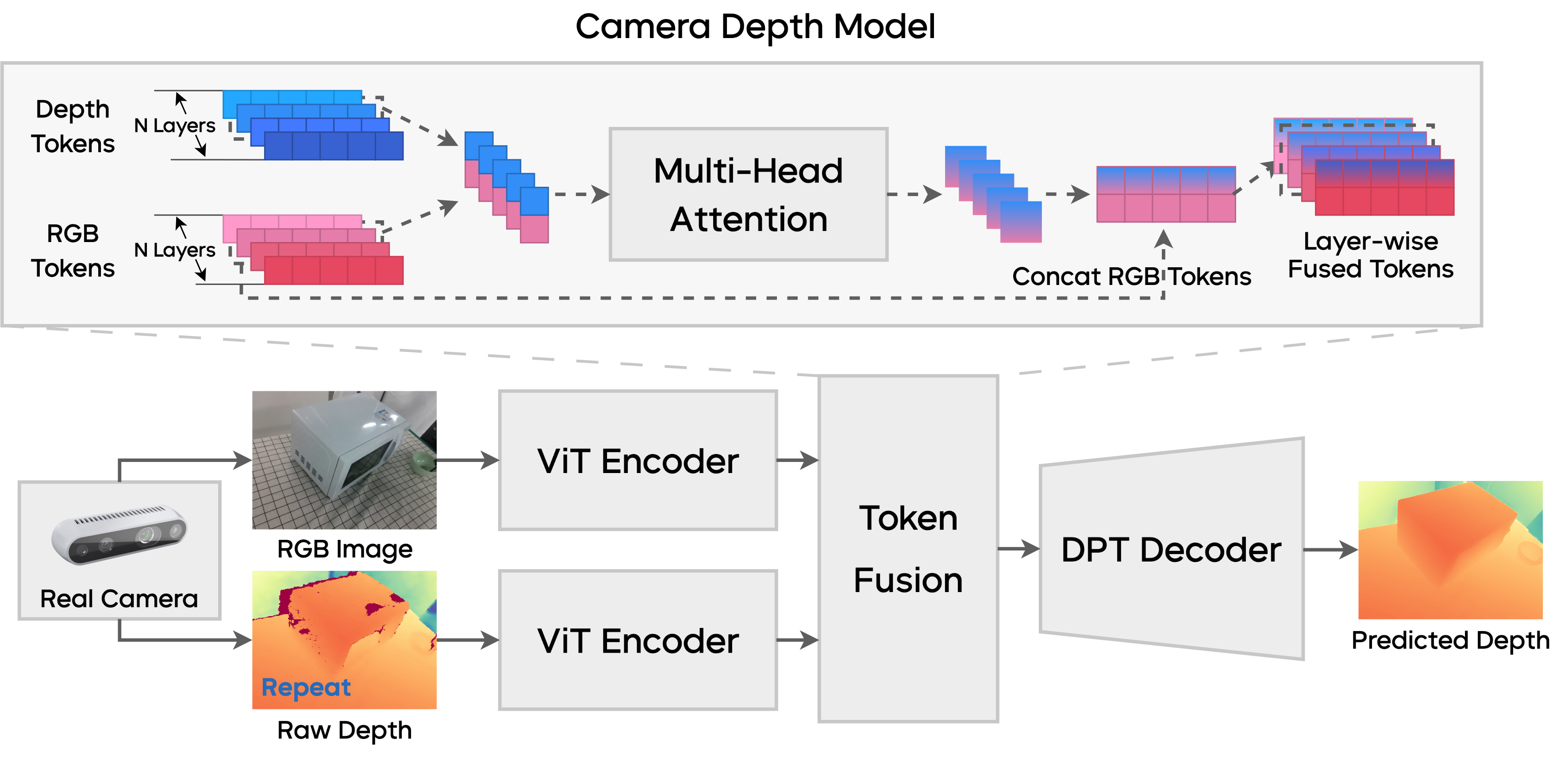
Manipulation as in Simulation:
Enabling Accurate Geometry Perception in Robots
1ByteDance Seed
2Shanghai Jiao Tong University
3Zhejiang University
4Tsinghua University
*Equal Contribution †Corresponding Authors
Minghuan did this work when he was at ByteDance Seed.